
Data Leadership in Practice: Building the AI-Ready Lakehouse - Part 1

TL;DR
This comprehensive blog post explores the transformative potential of lakehouse architectures and agentic AI in modern data leadership. It covers the evolution from traditional data systems to unified lakehouse architectures, emphasizing modularity, convergence of batch and streaming data, and governance by design. The post delves into tools like Databricks, Apache Iceberg, and Delta Lake, and discusses the operationalization of AI through ML tooling and real-world use cases like fraud detection and recommendation systems. It also highlights the role of agentic AI in automating business workflows and the importance of cost management, compliance, and control in data transformation. Leadership strategies at the intersection of AI, infrastructure, and product development are discussed to drive enterprise transformation and competitive advantage.
This article is part one of a five-part series on AI-ready data leadership and platform modernization.
From Fragmentation to Foundation: Building Enterprise-Scale Lakehouse Architectures
Traditional data systems, characterized by their fragmented and siloed nature, are proving inadequate in meeting the demands of modern AI applications. These legacy systems often struggle with scalability, flexibility, and the ability to handle the vast volumes of data generated today. As enterprises seek to leverage AI for real-time insights and decision-making, the limitations of conventional data architectures become glaringly apparent.
The Evolution of Data Systems
Historically, data management systems were designed with specific purposes in mind, leading to the creation of data silos. Data warehouses were optimized for structured data and complex queries, while data lakes were introduced to handle vast amounts of unstructured data. However, these systems often operated in isolation, leading to inefficiencies and data duplication.
Data Warehouses
Definition: Data warehouses are centralized repositories designed to support complex queries and provide insights into structured data. They use a schema-on-write approach, where data is structured and formatted before being stored.
Data warehouses have been the cornerstone of enterprise data management for decades. They are designed to support complex queries and provide insights into structured data. Data warehouses use a schema-on-write approach, where data is structured and formatted before being stored. This approach ensures data consistency and quality but can be inflexible and costly to scale.
Data Lakes
Definition: Data lakes are storage repositories that hold vast amounts of raw data in its native format until it is needed. They use a schema-on-read approach, where data is structured and formatted only when it is read.
Data lakes emerged as a solution to the limitations of data warehouses. They are designed to store vast amounts of unstructured and semi-structured data in its raw format. Data lakes use a schema-on-read approach, where data is structured and formatted only when it is read. This approach provides flexibility and scalability but can lead to data quality and governance issues.
The Need for a Unified Approach
The advent of AI and machine learning has necessitated a unified approach to data management. Modern AI applications require access to diverse data types and the ability to process this data in real-time. Traditional data architectures, with their siloed nature, are ill-equipped to meet these demands. This has led to the emergence of lakehouse architectures, which aim to combine the best features of data lakes and data warehouses.
Insight: The integration of data lakes and data warehouses into a unified lakehouse architecture addresses the need for both flexibility and structure, enabling real-time data processing and advanced analytics.
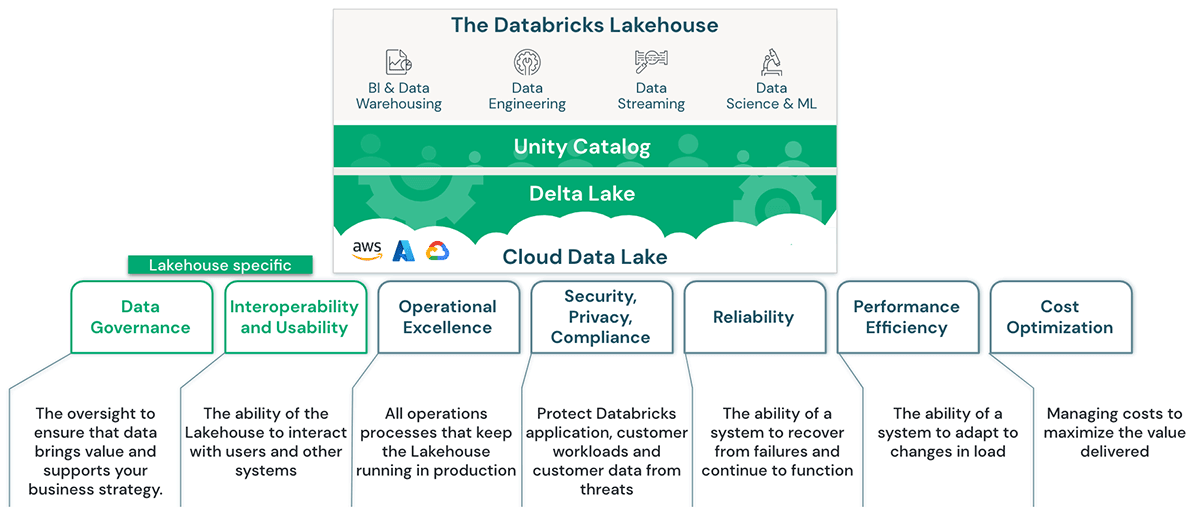
Source: Databricks Well-Architected Lakehouse Framework
Key Design Principles
To address these challenges, modern enterprises are adopting lakehouse architectures, which combine the best features of data lakes and data warehouses. The key design principles of these architectures include:
Modular, Decoupled Architecture
Definition: A modular, decoupled architecture emphasizes the separation of concerns, allowing different components of the data system to evolve independently. This enhances flexibility, scalability, and maintainability.
This principle emphasizes the separation of concerns, allowing different components of the data system to evolve independently. It ensures that changes in one part of the system do not necessitate changes in others, thereby enhancing flexibility and scalability.
Benefits of Modularity
- Flexibility: Modular architectures allow enterprises to adopt new technologies and approaches without disrupting existing systems. This flexibility is crucial in the rapidly evolving landscape of data management and AI.
- Scalability: Modular architectures enable enterprises to scale individual components of the system independently. This scalability is essential for handling the vast volumes of data generated by modern AI applications.
- Maintainability: Modular architectures simplify the process of maintaining and updating the system. Changes can be made to individual components without affecting the entire system, reducing the risk of unintended consequences.
Example
Insight: In an e-commerce platform, modular architecture allows customer data, inventory data, and transaction data to be managed by separate modules. This separation enables more agile development and easier maintenance.
Consider an e-commerce platform that needs to handle customer data, inventory data, and transaction data. In a modular architecture, each of these data types can be managed by separate modules. The customer data module can be updated to include new attributes without affecting the inventory or transaction data modules. This separation allows for more agile development and easier maintenance.
Batch and Streaming Convergence
Definition: Batch and streaming convergence refers to the integration of batch and streaming data processing capabilities within a single architecture, enabling comprehensive and timely data analysis.
Modern data architectures must support both batch and streaming data processing. This convergence allows enterprises to handle real-time data ingestion and processing alongside traditional batch operations, providing a more comprehensive and timely data analysis capability.
Benefits of Convergence
- Real-Time Insights: Converging batch and streaming data processing enables enterprises to gain real-time insights into their operations. This real-time capability is crucial for applications such as fraud detection, personalized recommendations, and anomaly detection.
- Comprehensive Analysis: Converging batch and streaming data processing provides a more comprehensive view of the data. Enterprises can analyze historical data alongside real-time data, enabling more accurate and timely decision-making.
- Efficiency: Converging batch and streaming data processing reduces the need for separate systems and processes. This convergence simplifies the data architecture and improves operational efficiency.
Example
Insight: A financial institution can use a lakehouse architecture to process transaction data in real-time for fraud detection while generating monthly reports through batch processes.
For instance, a financial institution may need to process transaction data in real-time to detect fraudulent activities while also running batch processes to generate monthly reports. A lakehouse architecture that supports both batch and streaming data processing can handle these requirements seamlessly. Real-time transaction data can be ingested and analyzed using streaming technologies like Apache Kafka, while batch processes can be executed using tools like Apache Spark.
Governance by Design
Definition: Governance by design involves embedding governance mechanisms within the architecture to ensure data quality, security, and compliance from the outset.
Embedding governance mechanisms within the architecture ensures data quality, security, and compliance from the outset. This proactive approach to governance helps in maintaining data integrity and trustworthiness across the enterprise.
Benefits of Governance by Design
- Data Quality: Embedding governance mechanisms within the architecture ensures that data is accurate, consistent, and reliable. This data quality is essential for making informed decisions and driving business value.
- Security: Embedding governance mechanisms within the architecture ensures that data is protected against unauthorized access, disclosure, and modification. This security is crucial for maintaining customer trust and complying with regulatory requirements.
- Compliance: Embedding governance mechanisms within the architecture ensures that data is managed in accordance with regulatory requirements. This compliance is essential for avoiding legal and financial penalties.
Example
Insight: In healthcare, embedding governance mechanisms ensures that patient data is accurate, secure, and compliant with regulations like HIPAA.
For example, a healthcare organization dealing with sensitive patient data must ensure that this data is protected and compliant with regulations like HIPAA. By embedding governance mechanisms within the lakehouse architecture, the organization can enforce data quality checks, access controls, and audit trails. This ensures that patient data is accurate, secure, and only accessible to authorized personnel.
Tools in Practice
Several tools and technologies are instrumental in building and maintaining lakehouse architectures:
Databricks, Apache Iceberg, Delta Lake
Definition: These platforms provide the foundational infrastructure for lakehouse architectures, offering robust data management and processing capabilities.
These platforms provide the foundational infrastructure for lakehouse architectures, offering robust data management and processing capabilities.
Databricks
Insight: Databricks unifies analytics, integrates with cloud storage, and fosters collaboration, making it a versatile platform for data management and AI integration.
Databricks provides a unified analytics platform that integrates with cloud storage systems to offer a lakehouse architecture. It supports both structured and unstructured data and provides capabilities for data engineering, data science, and machine learning.
- Unified Analytics: Databricks provides a unified platform for data engineering, data science, and machine learning. This unification simplifies the data architecture and improves operational efficiency.
- Cloud Integration: Databricks integrates with cloud storage systems such as AWS S3, Azure Blob Storage, and Google Cloud Storage. This integration enables enterprises to leverage the scalability and cost-effectiveness of cloud storage.
- Collaboration: Databricks provides a collaborative environment for data teams. This collaboration enables teams to work together more effectively and drive business value.
Apache Iceberg
Insight: Apache Iceberg's support for schema evolution, hidden partitioning, and multiple query engines makes it ideal for dynamic and scalable lakehouse architectures.
Iceberg is an open table format for huge analytic datasets. It provides features like schema evolution, hidden partitioning, and support for multiple query engines, making it an ideal choice for lakehouse architectures.
- Schema Evolution: Iceberg supports schema evolution, enabling enterprises to modify the structure of their data without disrupting existing queries and applications.
- Hidden Partitioning: Iceberg supports hidden partitioning, enabling enterprises to partition their data without exposing the partitioning scheme to users. This hidden partitioning improves query performance and simplifies data management.
- Query Engine Support: Iceberg supports multiple query engines, including Apache Spark, Apache Flink, and Presto. This support enables enterprises to leverage their existing query engines and tools.
Delta Lake
Insight: Delta Lake brings ACID transactions, data versioning, and schema enforcement to big data workloads, ensuring data consistency and reliability.
Delta Lake is an open-source storage layer that brings ACID transactions to Apache Spark and big data workloads. It provides capabilities for data versioning, schema enforcement, and unified batch and streaming processing.
- ACID Transactions: Delta Lake provides ACID transactions, ensuring data consistency and reliability. This ACID support is crucial for applications that require high data integrity.
- Data Versioning: Delta Lake provides data versioning, enabling enterprises to track changes to their data over time. This versioning support is essential for data governance and compliance.
- Schema Enforcement: Delta Lake provides schema enforcement, ensuring that data conforms to a predefined structure. This schema enforcement improves data quality and simplifies data management.
Apache Kafka, Spark Structured Streaming
Definition: These tools are essential for high-throughput data ingestion, enabling enterprises to handle large volumes of data in real-time.
These tools are essential for high-throughput data ingestion, enabling enterprises to handle large volumes of data in real-time.
Apache Kafka
Insight: Apache Kafka's high throughput, scalability, and fault tolerance make it ideal for building real-time data pipelines and streaming applications.
Kafka is a distributed event streaming platform that can handle trillions of events a day. It is used for building real-time data pipelines and streaming applications.
- High Throughput: Kafka can handle trillions of events a day, making it an ideal choice for high-throughput data ingestion.
- Scalability: Kafka is designed to scale horizontally, enabling enterprises to handle increasing volumes of data without disrupting existing systems.
- Fault Tolerance: Kafka is designed to be fault-tolerant, ensuring that data is not lost in the event of a system failure. This fault tolerance is crucial for applications that require high data reliability.
Spark Structured Streaming
Insight: Spark Structured Streaming's scalability, fault tolerance, and integration with other Spark components make it a powerful tool for stream processing.
Structured Streaming is a scalable and fault-tolerant stream processing engine built on the Spark SQL engine. It provides a high-level API for building streaming applications and integrates seamlessly with other Spark components.
- Scalability: Structured Streaming is designed to scale horizontally, enabling enterprises to handle increasing volumes of data without disrupting existing systems.
- Fault Tolerance: Structured Streaming is designed to be fault-tolerant, ensuring that data is not lost in the event of a system failure. This fault tolerance is crucial for applications that require high data reliability.
- Integration: Structured Streaming integrates seamlessly with other Spark components, including Spark SQL, DataFrames, and Datasets. This integration enables enterprises to leverage their existing Spark investments and tools.
dbt, Airflow, Dagster
Definition: These technologies facilitate data transformation and pipeline orchestration, ensuring that data flows smoothly through various stages of processing and analysis.
These technologies facilitate data transformation and pipeline orchestration, ensuring that data flows smoothly through various stages of processing and analysis.
dbt (data build tool)
Insight: dbt's SQL-based approach, modularity, and collaboration features make it a powerful tool for transforming raw data into analysis-ready datasets.
dbt is a transformation tool that enables data teams to transform raw data in their warehouses into clean, analysis-ready datasets. It uses SQL and a modular approach to build data transformation pipelines.
- SQL-Based: dbt uses SQL for data transformation, enabling data teams to leverage their existing SQL skills and tools.
- Modularity: dbt uses a modular approach to build data transformation pipelines, enabling data teams to reuse and share code. This modularity improves operational efficiency and simplifies data management.
- Collaboration: dbt provides a collaborative environment for data teams, enabling teams to work together more effectively and drive business value.
Airflow
Insight: Airflow's programmatic authoring, scheduling, and monitoring features make it a versatile platform for building and managing data pipelines.
Apache Airflow is a platform to programmatically author, schedule, and monitor workflows. It provides a rich set of features for building and managing data pipelines.
- Programmatic Authoring: Airflow enables data teams to programmatically author workflows, leveraging their existing programming skills and tools.
- Scheduling: Airflow provides a rich set of features for scheduling workflows, enabling data teams to automate and orchestrate data pipelines.
- Monitoring: Airflow provides a rich set of features for monitoring workflows, enabling data teams to track the status and performance of data pipelines.
Dagster
Insight: Dagster's unified interface, extensive integrations, and testing capabilities make it a robust platform for data orchestration.
Dagster is a modern data orchestration platform that provides a unified interface for defining, executing, and monitoring data pipelines. It supports a wide range of integrations and provides capabilities for testing and debugging pipelines.
- Unified Interface: Dagster provides a unified interface for defining, executing, and monitoring data pipelines, simplifying the data architecture and improving operational efficiency.
- Integrations: Dagster supports a wide range of integrations with popular data tools and platforms, enabling data teams to leverage their existing investments and tools.
- Testing and Debugging: Dagster provides capabilities for testing and debugging pipelines, enabling data teams to ensure the reliability and accuracy of data pipelines.
S3, Glue, Redshift, Athena
Definition: These services offer flexible storage and query optimization, allowing enterprises to store vast amounts of data cost-effectively and retrieve it efficiently when needed.
These services offer flexible storage and query optimization, allowing enterprises to store vast amounts of data cost-effectively and retrieve it efficiently when needed.
S3 (Simple Storage Service)
Insight: S3's scalability, cost-effectiveness, and reliability make it a popular choice for storing and retrieving vast amounts of data.
S3 is a scalable object storage service provided by AWS. It is designed to store and retrieve any amount of data from anywhere on the web.
- Scalability: S3 is designed to scale horizontally, enabling enterprises to store and retrieve vast amounts of data without disrupting existing systems.
- Cost-Effectiveness: S3 is designed to be cost-effective, enabling enterprises to store data at a low cost.
- Reliability: S3 is designed to be highly reliable, ensuring that data is not lost in the event of a system failure. This reliability is crucial for applications that require high data integrity.
Glue
Insight: AWS Glue's serverless environment, data catalog, and integration with other AWS services make it a powerful tool for ETL and metadata management.
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load data for analytics. It provides a serverless environment for running ETL jobs and a data catalog for managing metadata.
- Serverless: Glue provides a serverless environment for running ETL jobs, simplifying the data architecture and improving operational efficiency.
- Data Catalog: Glue provides a data catalog for managing metadata, enabling data teams to discover, understand, and govern their data.
- Integration: Glue integrates with a wide range of AWS services, including S3, Redshift, and RDS. This integration enables enterprises to leverage their existing AWS investments and tools.
Redshift
Insight: Amazon Redshift's high performance, scalability, and cost-effectiveness make it a popular choice for data warehousing and complex query processing.
Amazon Redshift is a fully managed data warehouse service that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools.
- Performance: Redshift is designed to provide high performance for complex queries and large datasets. This performance is crucial for applications that require real-time insights and decision-making.
- Scalability: Redshift is designed to scale horizontally, enabling enterprises to handle increasing volumes of data without disrupting existing systems.
- Cost-Effectiveness: Redshift is designed to be cost-effective, enabling enterprises to analyze data at a low cost.
Athena
Insight: Amazon Athena's serverless nature, standard SQL support, and cost-effectiveness make it a versatile tool for interactive querying and data analysis.
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. It is serverless, so there is no infrastructure to manage, and you pay only for the queries you run.
- Serverless: Athena is serverless, simplifying the data architecture and improving operational efficiency.
- Standard SQL: Athena uses standard SQL for querying data, enabling data teams to leverage their existing SQL skills and tools.
- Cost-Effectiveness: Athena is designed to be cost-effective, enabling enterprises to analyze data at a low cost.
The Strategic Foundation
The lakehouse architecture is not merely a data layer; it is the strategic foundation for product development, AI integration, and automation. By providing a unified platform for data management, it enables enterprises to derive actionable insights and drive innovation.
Example
Insight: A retail organization can leverage a lakehouse architecture to integrate customer data, sales data, and inventory data, enabling AI-driven personalized recommendations, demand forecasting, and inventory optimization.
For example, a retail organization can use a lakehouse architecture to integrate customer data, sales data, and inventory data. This integrated data can be used to build AI models for personalized recommendations, demand forecasting, and inventory optimization. The lakehouse architecture provides the flexibility to handle diverse data types and the scalability to support real-time analytics, enabling the organization to make data-driven decisions and drive business growth.
Leadership takeaway: Embed governance from the start, not as a retrofitted control.
Also read: